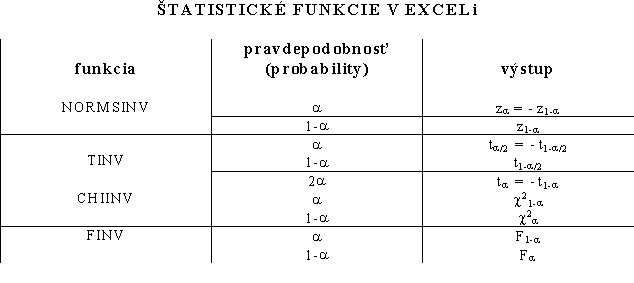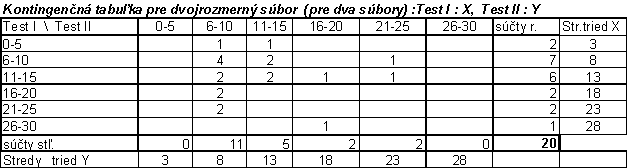
Štatistiky počítané z kontingenčnej
tabuľky: ![]()
![]()
Kovariancia ![]() Korelačný
koeficient
Korelačný
koeficient ![]()
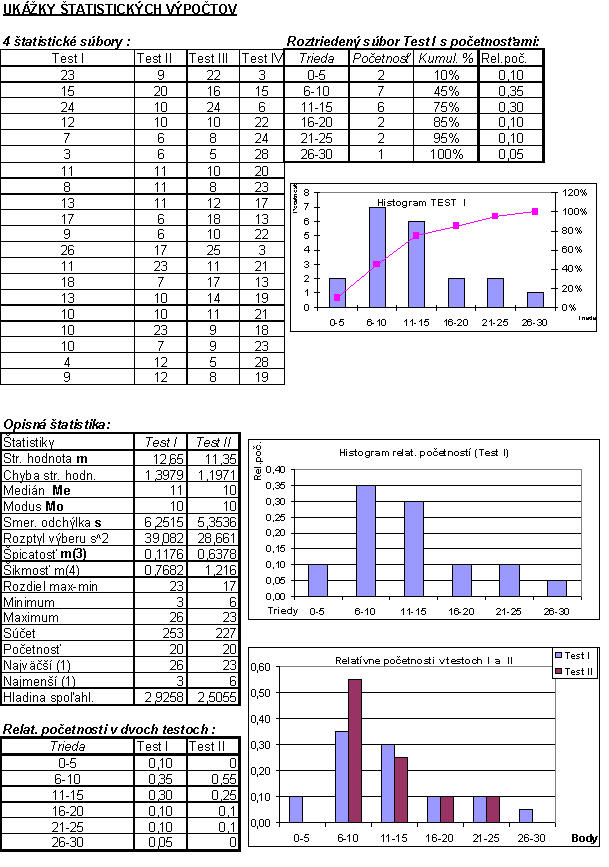
Základné štatistiky súboru
Aritmetický priemer ![]() vyjadruje objem hodnôt premennej X
pripadajúci v priemere na
jednu jednotku súboru
vyjadruje objem hodnôt premennej X
pripadajúci v priemere na
jednu jednotku súboru 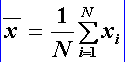
N - rozsah súboru
![]() - hodnota premennej X u
i-tej jednotky
- hodnota premennej X u
i-tej jednotky
Variačné rozpätie vr je rozdiel
medzi najväčšou a najmenšou hodnotou
kvantitatívneho znaku vr = xmax - xmin
Rozptyl ![]() predstavuje priemerný
štvorec odchýlky od priemeru.
predstavuje priemerný
štvorec odchýlky od priemeru.

Štandardná (smerodajná) odchýlka 
Štandardná chyba (chyba strednej hodnoty) 
Modus Mo
je najčastejšie sa vyskytujúca hodnota znaku X, resp., v prípade triedeného súboru
hodnota reprezentanta triedy s najväčšou absolútnou početnosťou.
Medián Me delí súbor na 2 skupiny, z ktorých prvá obsahuje 50% štatistických jednotiek, ktoré majú hodnotu znaku X menšiu ako medián druhá obsahuje 50% zvyšných štatistických jednotiek, ktoré majú hodnotu väčšiu ako medián.
Koeficient šikmosti ![]() charakterizuje symetriu rozdelenia.
charakterizuje symetriu rozdelenia.
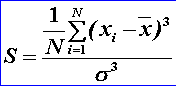
Ak S = 0 rozdelenie je
symetrické, ak S > 0 je rozdelenie
oproti symetrickému zošikmené doľava (častejší výskyt menších hodnôt), ak S
< 0, rozdelenie je oproti symetrickému zošikmené doprava (častejší výskyt väčších hodnôt).
Koeficient
špicatosti
K charakterizuje strmosť rozdelenia.
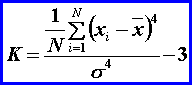
Ak K = 0, rozdelenie je rovnako špicaté ako normálne, ak K > 0,
rozdelenie je „špicatejšie“ ako normálne, a ak K < 0, hovoríme o
„plochšom“ rozdelení ako je normálne.
![]()
EXCEL/Nástroje / Analýza údajov /
Popisná štatistika
|
Stredná hodnota |
|
|
Chyba strednej hodnoty |
|
|
Medián |
Me,
|
|
Modus |
M0 |
|
Smerodajná odchýlka (výberová; odhad s) |
|
|
Rozptyl výberu (odhad disperzie s2 ) |
|
|
Špicatosť |
S, m4 |
|
Šikmosť |
K, m3 |
|
Rozdiel max-min |
vr |
|
Minimum |
xmin |
|
Maximum |
xmax |
|
Súčet |
|
|
Početnosť |
n |
|
Hladina spoľahlivosti (a; štandardne
0,05; 95,0%) |
|
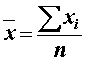

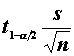
Bodový a intervalový odhad základných parametrov
Bodový
odhad priemeru m základného súboru ![]()
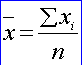
Bodový
odhad rozptylu s2 základného súboru ![]() =
= 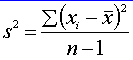
Bodový
odhad štandardnej (smerodajnej) odchýlky s základného súboru
![]()
Interval
spoľahlivosti priemeru m
1.
s2 poznáme 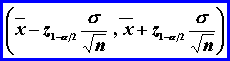
·
1-a je pravdepodobnosť, že m sa nachádza v danom
intervale
nazývame ju spoľahlivosť odhadu, volíme ju blízku
1
·
a je hladina
spoľahlivosti, zvyčajne volíme a= 0,01; 0.05; 0.1
·
![]() je
je ![]()
![]() kvantil normovaného normálneho rozdelenia)
kvantil normovaného normálneho rozdelenia)
2.
s2
nepoznáme a výberový súbor je veľký ![]()
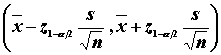
3.
s2 nepoznáme a výber. súbor je malý (n<30) 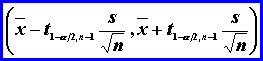
·
![]() je
je
![]() kvantil Studentovho t-rozdelenia s n-1 stupňami
volnosti.
kvantil Studentovho t-rozdelenia s n-1 stupňami
volnosti.
Interval
spoľahlivosti rozptylu s2 
![]() sú
sú ![]() a
a ![]() kvantily c2 – rozdelenia
kvantily c2 – rozdelenia
Interval
spoľahlivosti štand. odchýlky s : odmocnina
Testovanie hypotéz o zhode parametrov
(stredná hodnota, rozptyl) dvoch základných
súborov
hypotéza (nulová H0, alternatívna)
testovacia
štatistika
hladina
významnosti, kritická hodnota
oblasť
prijatia (zamietnutia) nulovej hypotézy, p-hodnota
POSTUP
I. Sformulujeme nulovú hypotézu H0 a alternatívnu hypotézu H1
H0: ![]() H0 :
H0 : ![]()
H1: 1. ![]() H1 : 1.
H1 : 1. ![]()
2. ![]() 2.
2. ![]()
3. ![]() 3.
3. ![]()
II. Voľba chyby (1. druhu) a , t.j. pravdepodobnosti, s akou zamietneme
pravdivú hypotézu H0
(hladina významnosti)
III. Voľba
a výpočet testovacej štatistiky
IV.
Určenie oblasti prijatia, resp. zamietnutia H0 a rozhodnutie o prijatí,
resp. zamietnutí H0
Ad1. H0 : ![]() H1 :
H1 : ![]()
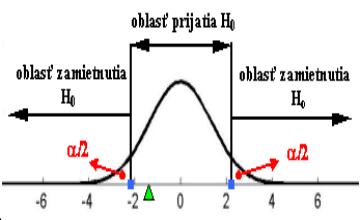
a hladina
spoľahlivosti, chyba 1. druhu
![]() kritická hodnota
kritická hodnota
![]() testovacia
štatistika
testovacia
štatistika
Ad 2. H0: ![]() H1:
H1: ![]()
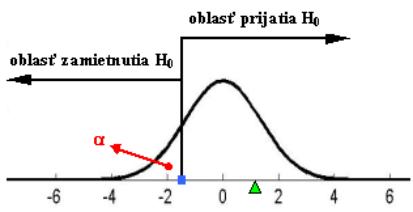
Ad 3. H0: ![]() H1:
H1:
![]()
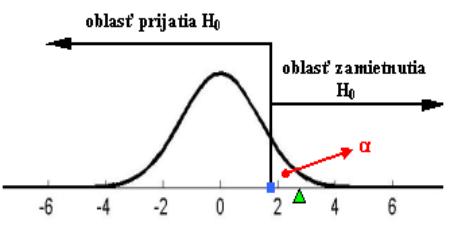
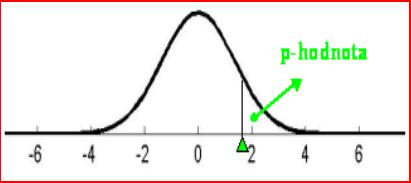
p-hodnota - najnižšia hladina na zamienutie H0
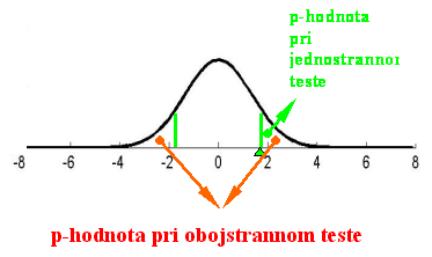
TESTY
NORMALITY
TEST NORMALITY PODĽA SHAPIRA –WILKA
Predpoklady
![]()
HYPOTÉZY
H0: náhodný výber pochádza zo súboru
s normálnym rozdelením
H1: náhodný výber nepochádza zo súboru s normálnym
rozdelením
Testovacia štatistika 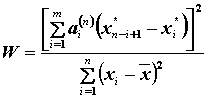
![]() - hodnoty znaku v náhodnom výbere
- hodnoty znaku v náhodnom výbere
![]() - hodnoty znaku usporiadané podľa veľkosti
- hodnoty znaku usporiadané podľa veľkosti
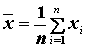
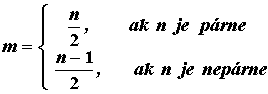
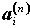 - koeficienty
z tabuľky Tab W.
- koeficienty
z tabuľky Tab W.
![]() - tabuľková hodnota
pre dané n a hladinu významnosti
- tabuľková hodnota
pre dané n a hladinu významnosti ![]() alebo
alebo![]()
Záver testu
H0 nezamietame, ak
![]()
TEST NORMALITY PODĽA D’AGOSTINA
Predpoklady: ![]()
HYPOTÉZY
H0: náhodný výber pochádza zo súboru
s normálnym rozdelením
H1: náhodný výber nepochádza zo súboru
s normálnym rozdelením
Testovacia štatistika 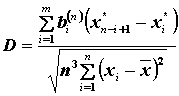
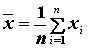 ,
, 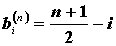 ,
, 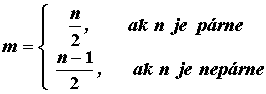
![]() ,
,
![]() - tabuľkové hodnoty pre dané
n
a hladinu významnosti
- tabuľkové hodnoty pre dané
n
a hladinu významnosti ![]() alebo
alebo ![]() , pozri výpis v tabuľke.
, pozri výpis v tabuľke.
Transformovaná hodnota 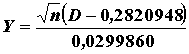
Záver testu : H0 nezamietame, ak ![]()
|
|
|
1- |
||
|
n |
0,005 |
0,025 |
0,975 |
0,995 |
|
30 |
-4,19 |
-2,91 |
0,830 |
0,941 |
|
36 |
-4,09 |
-2,85 |
0,917 |
1,05 |
|
40 |
-4,03 |
-2,81 |
0,964 |
1,11 |
|
50 |
-3,91 |
-2,74 |
1,06 |
1,24 |
|
60 |
-3,81 |
-2,68 |
1,13 |
1,34 |
|
90 |
-3,61 |
-2,57 |
1,28 |
1,54 |
|
100 |
-3,57 |
-2,54 |
1,31 |
1,59 |
ANOVA
(ANALÝZA ROZPTYLU)
metóda na
porovnanie priemerov niekoľkých základných súborov
Predpoklady
·
výberové súbory pochádzajú zo súborov s normálnym rozdelením
·
výberové súbory sú navzájom nezávislé
· rozptyly základných súborov sa rovnajú
jednofaktorová ANOVA
Hypotézy
H0: m1 = m2 = . . . = mr
(priemerné hodnoty nezávisia od hodnoty faktora)
(Predpokladáme,
že úroveň priemerov niekoľkých ZS závisí len od jedného faktora)
H1: nie všetky mi sa rovnajú
(priemerné hodnoty závisia od hodnoty
faktora; aspoň 2 priemery sa nerovnajú – nezávisia od faktora)
faktor: skupina, základný súbor
xij -
j-ta
hodnota štatistickej jednotky z i-teho
výberového súboru
![]() - i-ty výberový
priemer
- i-ty výberový
priemer
![]() -
celkový výberový priemer
-
celkový výberový priemer
![]() celková odchýlka
celková odchýlka
![]()
celková odchýlka
= medziúrovňová+vnútroúrovňová
(reziduálna) odchýlka
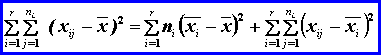
![]()
SSTotal – súčet štvorcov
celkových odchýlok
(celková variabilita údajov)
SST - súčet štvorcov medziúrovňových odchýlok
(variabilita spôsobená úrovňami faktora, vysvetlená faktorom)
SSE - suma štvorcov vnútroúrovňových
(reziduálnych) odchýlok
(variabilita spôsobená náhodnými vplyvmi, nevysvetlená faktorom)
EXCEL/Nástroje/Analýza údajov/Anova: jeden faktor
Tabuľka analýzy rozptylu
Zdroj
variability |
SS(suma štvorcov odchýlok) |
rozdiel d.f.(stupne voľnosti) |
MS(priemer
štv. odch.) |
F testov.
štatistika |
Hodnota P |
F-krit
|
|
Medzi výbermi |
SST |
r-1 |
MST
medziúrovňové |
|
najnižšia hodnota na zamietnutie
H0 |
F1-a(r-1,n-r) |
|
Všetky výbery |
SSE |
n-r |
MSE
reziduálne |
|
|
|
|
celkom |
SSTotal) |
n-1 |
|
|
|
|
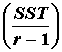
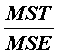

Vyhodnotenie
testu:
H0 :
priemery základných súborov sa rovnajú
Oblasť zamietnutia
H0: F ³ F-krit, resp.
ak a< P-hodnota
(Ak H0 platí,
F kolíše okolo 1; ak F>>1, potom sa priemery ZS nerovnajú.)
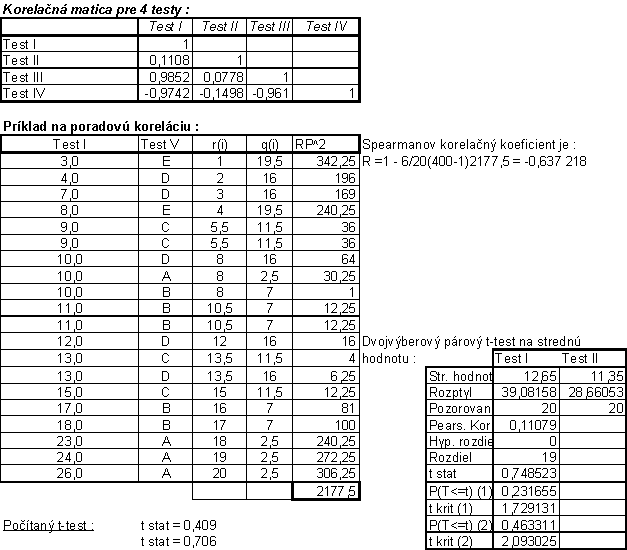
EXCEL/Nástroje
/ Analýza údajov /
Korelácia
korelácia je normovanou mierou vzájomnnej lineárnej závislosti medzi hodnotami
dvoch premenných X,Y
koeficient
korelácie 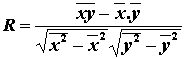
![]()
R nadobúda hodnotu blízku
1 vysoká
priama lineárna závislosť
R nadobúda hodnotu blízku
-1 vysoká
nepriama lineárna závislosť
R nadobúda hodnotu blízku
0,7
stredná priama lineárna
závislosť
R nadobúda hodnotu blízku
- 0,7
stredná nepriama lineárna
závislosť
R nadobúda hodnotu blízku
0,5 slabá priama lineárna závislosť
R nadobúda hodnotu blízku
-0,5 slabá nepriama lineárna závislosť
R nadobúda hodnotu
blízku 0 premenné sú nekorelované
Analýza vzájomnej závislosti hodnôt
Modelovanie
príčinnej závislosti
Y=f (X)
X - nezávisle premenná (príčina)
Y - závisle premenná (následok)
Regresná (vyrovnávajúca ) priamka
![]()
·
![]() - očakávaná
(vyrovnaná) hodnota premennej Y pre danú hodnotu
- očakávaná
(vyrovnaná) hodnota premennej Y pre danú hodnotu
premennej X
·
![]() - hodnota premennej X
- hodnota premennej X
·
![]() - očakávaná hodnota premennej Y, ak x =
0
- očakávaná hodnota premennej Y, ak x =
0
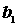 - regresný
koeficient - udáva,
o koľko sa zmení
- regresný
koeficient - udáva,
o koľko sa zmení 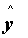 , ak sa
hodnota X
zmení o 1 mernú
jednotku
, ak sa
hodnota X
zmení o 1 mernú
jednotku
![]()
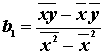
![]()
Koeficient
determinácie R2 vyjadruje stupeň príčinnej závislosti premennej Y od
premennej X , t.j.
aký podiel variability premennej Y je
vysvetlený regresným modelom
EXCEL/Nástroje
/ Analýza údajov /
Regresia
|
|
|
Regresná štatistika |
|
|
Násobné R |
R |
|
Hodnota spoľahlivosti R |
R2 |
|
Nastavená hodnota spoľahlivosti R |
R2 (upr) |
|
Chyba str. hodnoty |
srez |
|
Pozorovaní |
n |
|
Regresná priamka: y = b0 + b1
x Lineárny regresný model: y = b0 + b1
x + e e...
náhodná chyba, biely šum |
|
|
Rozdiel (stupne voľnosti) |
SS |
MS |
F |
Významnosť F |
|
Regresia |
1 |
SSR |
MSR |
F |
p-hodnota |
|
Rezíduá |
n-2 |
SSE |
MSE |
F=MSR/MSE= |
H0: lineárny model nie je štatisticky významný (zamieta sa pri veľmi
malej p-hodnote), alebo ak F>Fa(1,n-2) |
|
Celkom |
n-1 |
SSY |
|
=(SSR/1)/(SSE/n-2) |
|
|
Koeficienty |
Chyba str. hodnoty |
t stat |
Hodnota P |
Dolná 95% |
Horná 95% |
Dolná 99.0% |
Horná 99.0% |
|
Hranice |
b0 |
Sb0 |
b0/Sb0 |
H0:B0=0 |
interval
spoľahlivosti pre B0 |
interval
spoľahlivosti pre B0 |
||
|
X |
b1 |
Sb1 |
b1/Sb1 |
H0:B1=0 |
interval
spoľahlivosti pre B1 |
interval
spoľahlivosti pre B1 |
||
SSE (súčet štvorcov chýb) = ![]()
Ak SSE = SSR ![]() Y a X sú
nezávislé.
Y a X sú
nezávislé.
Ak SSE > SSR ![]() lineárny vzťah Y a X vysvetľuje variabilitu Y podielom
(SSR/SSY).100% = R2 . Pri opačnej relácii je vzťah vysvetlený
nedostatočne.
lineárny vzťah Y a X vysvetľuje variabilitu Y podielom
(SSR/SSY).100% = R2 . Pri opačnej relácii je vzťah vysvetlený
nedostatočne.